ElasticSearch Tutorial: Das Konzept verstehen
Der Suchserver ElasticSearch ist schwer im Kommen. Geschwindigkeit, Anpassbarkeit und Verlässlichkeit sind nur einige wenige seiner Stärken. Bevor man sich aber an die Implementierung dieser mächtigen Such-Software wagt, sollte man erst die Funktionsweise und die Architektur von ElasticSearch verstehen.
ElasticSearch Step by Step: Fallbeispiel
Nehmen wir hierzu einen Usecase, welcher nicht unbedingt nur der reinen Phantasie entspringt: Wir möchten eine OnlineMarket-Plattform auf die Beine stellen, wo man sich als Käufer und Verkäufer anmelden kann. So eine Art Amazon Marketplace oder eBay. Soweit so gut. Der Punkt hier ist aber: Die Artikel und Verkäuferdaten sollten durchsuchbar sein. Und zwar nicht irgendwie im 0815-Stil mit billigen SQL-Queries wie
SELECT * FROM articles WHERE name LIKE '%$searchTerm%' OR description '%$searchTerm%' sondern richtig professionell. Tja, dazu muss wohl eine Searchengine her.
ElasticSearch Tutorial: Eindeutig solide Basis
Ein sehr weit verbreiteter Suchserver ist Apache Lucene. Wikimedia zum Beispiel verwendete bis vor kurzem diese Such-Engine. Lucene ist sehr gut getestet und läuft stabil und schnell, keine Frage. Das Problem ist aber, dass man auf Lucene nur mit Java Zugriff hat, die Implementierung und Konfiguration etwas aufwändiger sind und z.B. die Datenstruktur vor dem Indizieren bereits bekannt sein muss. Diese und viele weitere Eigenheiten versucht ElasticSearch auszubügeln. An dieser Stelle sei gesagt, dass ElasticSearch kein Abklatsch von Lucene ist und es auch nicht versucht abzulösen, sondern ein Wrapper um Lucene ist. Deswegen ist auch Wikimedia auf ElasticSearch umgestiegen. Und deswegen machen auch wir den Start mit ElasticSearch.
ElasticSearch Tutorial: Architektur und Konzepte
Um die Funktionsweisen von ElasticSearch zu verstehen, muss man aktzepieren, dass es zwei Sachen gibt, mit denen man sich intensiv beschäftigen muss: Das Physikalische und das Logische innerhalb von ElasticSearch.
ElasticSearch verstehen: Logische Infrastruktur
Eine ElasticSearch Suite, so will ich das mal an dieser Stelle nennen, ist in Indexe, Typen und Dokumente aufgeteilt:
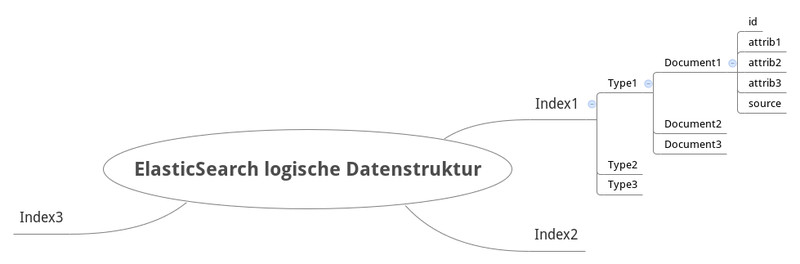
Die Terminologie verwirrt auf den ersten Blick, deswegen hier eine Step by Step Erklärung:
ElasticSearch: Was ist ein Index?
Einen ElasticSearch Index (siehe Index1, Index2 und Index2 in der Infografik) kann man mit einer Datenbank vergleichen. Dort werden alle Daten abgelegt, die irgendwann durchsucht werden sollen. Dieser Index wird in sogenannte Typen aufgeteilt.
ElasticSearch: Typen
Typen (siehe Type1, Type2, Type3 in der Infografik) sind für unsere Such-Engine wie Tabellen für eine Datenbank. Und wie eine normale Datenbank mehrere Tabellen beinhalten kann, kann auch unser Index mehrere Typen unterbringen. Die Typen selber lassen sich aber natürlich noch ein wenig zerlegen – in Dokumente.
ElasticSearch: Dokumente mit Properties
ElasticSearch ist zwar keine klassische Datenbank, benötigt zum geschmeidigen Funktionieren aber dennoch etwas Struktur in den Daten. Die Dokumente (siehe insbesondere den Zweig Document1 in der Infografik) werden deshalb mit Eigenschaften (Properties) versehen. Dort sind dann die eigentlichen Daten für die Suche gespeichert.
Nennenswert ist hier das Feld source: Es beinhaltet standardmäßig alle Originaldaten, anhand deren die Attribute (sieh attrib1, attrib2, attrib3) entstanden sind, unabhängig davon, ob es diese Daten sinnvoll waren oder sogar Syntaxfehler gehabt haben. Ja, ElasticSearch speichert es einfach.
Logische Infrastruktur: Zusammenfassung
ElasticSearch speichert also alle Daten in Index, die wiederum in Typen und Dokumente mit Eigenschaften aufgesplittet sind. Das war es zur Logik. Aber wie werden die Daten von ElasticSearch physikalisch abgelegt?
ElasticSearch erklärt: Physikalische Infrastruktur
Wenn man Daten hat, muss man diese irgendwo speichern. Logisch: Auf irgendwelchen Festplatten. Und am Besten redundant und mit schnellem Zugriff. Genau das macht auch ElasticSearch für unsere Such-Daten.

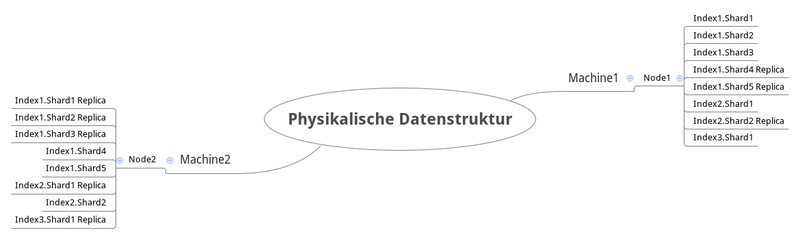
Nehmen wir mal an, wir kaufen zwei Server, die fleißig an unseren Suchanfragen arbeiten sollen. Wenn der eine (im oberen Bild Machine1 genannt) aufgrund von schlechter Laune oder Überhitzung (zum Zeitpunkt des Verfassens dieses Artikels waren es 31 Grad im Büro) die laufende ElasticSearch-Instanz (Node1) nicht mehr bedienen kann, schreitet dann eben der zweite Server Machine2 ein auf dem ebenfalls eine Instanz Node2 läuft. Sie arbeiten also Hand in Hand und verteilen zudem die Sucharbeit, weil sich beide im selben Cluster befinden.
Die Daten eines ElasticSearch Index werden aufgesplittet in sogenannte Shards. Wörtlich übersetzt heißt es „Scherbe“ und verhält sich auch so. Denn wenn man einen Node mit den Default-Einstellungen startet und ihn mit Daten füttert, erstellt er automatisch einen Index mit fünf Shards. Er zersplittert sozusagen den Index wie einen Spiegel in fünf Scherben. Und wenn zusätzliche Nodes im Cluster anwesend sind, verteilt ElasticSearch die Scherben mehr oder weniger gerecht auf die Nodes. Der eine bekommt also drei der andere zwei Shards.

Und weil unsere Datenscherben so wertvoll sind, sollte man wenigstens ein Backup davon erstellen. Auch das macht ElasticSearch für uns. Man kann dem System nämlich sagen, wie viele Replikate der Shards man haben möchte. Diese werden dann intelligent auf die Nodes aufgeteilt. Beispiel:
| Shard-Nr. | Shard-Node | Replikat-Node |
|---|---|---|
| 1 | Node1 | Node2 |
| 2 | Node1 | Node2 |
| 3 | Node1 | Node2 |
| 4 | Node2 | Node1 |
| 5 | Node2 | Node1 |
Beim Ausfall eines Nodes werden dann die Replikate in einen normalen Shard umgewandelt und somit bleibt die Suchfunktion unbeeinträchtigt.
Bei einer ElasticSearch Suite mit zwei Nodes und folgender Konstellation …
| Index-Name | Shards-Anzahl |
|---|---|
| Index1 | 5 |
| Index2 | 2 |
| Index3 | 1 |
… sieht das ganze schematisch wie folgt aus:
ElasticSearch: Konkretes Beispiel mit Strukturen
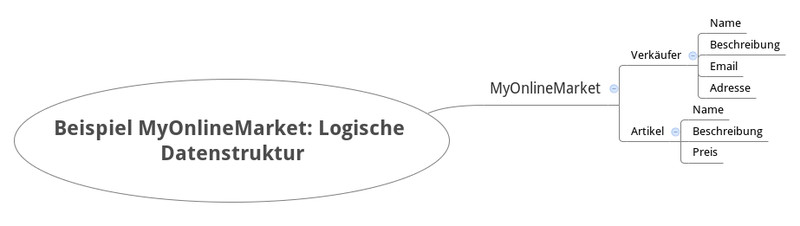
Um das Wissen nun etwas zusammenzufassen und zu konkretisieren werden wir jetzt nochmal zu unserem Beispiel MyMarketOnline zurückkehren. Wir lassen ElasticSearch einen Index MyOnlineMarket erstellen. Dort werden die Typen Verkäufer und Artikel angelegt und mit verschiedenen Properties gefüllt. Nachdem ElasticSearch mit Daten sattgefüttert wurde, muss es diese Daten irgendwo speichern. In unserem Beispiel werden wir für dieses kleine Projekt nur einen Shard verwenden, also als die kleinste Fallback-Lösung. Dieser Shard wir im Node1 in Original gespeichert und im Node2 als Replikat. Somit sind wir auf der sicheren Seite. Die nachfolgenden Infografiken verdeutlichen noch ein wenig mehr den Zusammenhang:

ElasticSearch Infrastruktur verstehen sinnvoll
Mit diesen Kenntnissen kann man sich jetzt an kleinere und größere ElasticSearch-Projekte setzen. Wenn dann ein Shard im Cluster auf einen Node umzieht oder bestimmte Indexe Probleme machen, steht man nicht mehr vor böhmischen Dörfern. Jetzt weiß man (hoffentlich), wo man was zu analysieren und anzupacken hat.
Bildnachweis: © Titelbild: shutterstock – Md Aziman, alle anderen schwarzer.de
Auch Interessant:

„Welche Aufgaben sollte Künstliche Intelligenz übernehmen?“ Zwei Vorschläge und ein Gedanke.
Es vergeht kein Tag, an dem man nicht liest,…

Typo3 6.2 Fluid und eigene ViewHelper
In der Entwicklung von Typo3 Extbase-Extensions…

Datenstrukturen von Extbase-Extensions anpassen
Anpassen von Typo3-Extbase-Extensions ist nicht…

Extension-Entwicklung mit Extbase (Teil 2)
Das Grundgerüst: Extension-Entwicklung mit…